Everything is just text
(rambling about HTML, the nature of data, web, etc. TK)
A brief primer to HTML
It's worth knowing a minimum of HTML terminology before we begin debugging web pages.
Here is the raw HTML code behind a single HTML element:
<strong>Hello</strong>
An HTML element contains a tag, or more often, a starting and closing tag. In this case, the tag's name is <strong>, and the element consists of both a starting tag – <strong> – and a closing tag – </strong>.
The word Hello is a raw text element. As it's contained within the starting and closing <strong> tags, we can think of the Hello text element as being a child of the element denoted by the <strong> tag.
When the above snippet is rendered by the browser, this is what the element looks like:
Hello
Attributes
Not all HTML elements contain a pair of tags, nor have children elements. For instance, here's the <img> tag used to denote an image element:
<img src="http://www.compjour.org/files/images/stanford-pano.jpg" alt="Stanford">
While the <img> tag is lone and childless, it does contains two attributes:
src- the URL for the actual image filealt- the text to show if the image file URL is invalid, or if the page is being read by a non-visual browser (such as a screen-reader for the visually impaired).
Note: For HTML elements that consist of a starting and closing tag, the attributes are always defined in the starting tag.
As I stated earlier in this lesson, HTML documents are just text. When the browser renders multimedia elements, such as photos and movies, it's a result of the browser following the URLs denoted in the HTML elements' attributes.
In this case, the <img> element has a src attribute which points to where the browser can find a photo to display:

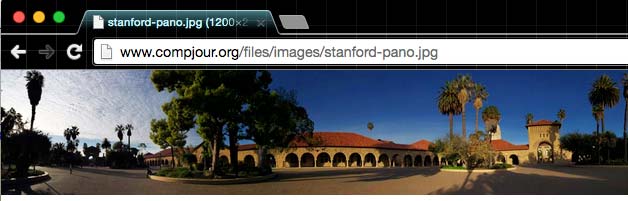
We can visit the URL directly by copying and pasting the URL below into the browser's address bar:
http://www.compjour.org/files/images/stanford-pano.jpg
Be careful not to mistake the result of this copy-pasting-hitting-Enter as visiting an actual webpage. Instead, what a modern web browser will do is just act like an image viewer. Since we're still in the web browser, it seems as if it's an actual webpage:
Nested elements
The raw HTML for a hyperlink looks like this:
<a href="http://www.stanford.edu">Stanford's homepage</a>
(Why <a>? Hyperlinks are also referred to as anchor tags)
Again, href is the attribute, and http://www.stanford.edu is the value of that attribute. The <a> tags contain the raw text element Stanford's homepage. This is how the browser renders that snippet:
However, HTML tags can contain other tags as well. In the following snippet, a hyperlink contains an image element – i.e. the image is the child, or is nested, within the hyperlink:
<a href="http://www.stanford.edu">
<img src="http://www.compjour.org/files/images/stanford-pano.jpg" alt="Stanford">
</a>
The browser renders this code as an image that, when clicked, will send the user to http://www.stanford.edu:
The DOM Tree
DOM is short for Document Object Model, and DOM tree is the term used to refer to the internal representation of a given webpage, i.e. the HTML elements as interpreted by the browser.
It's easiest to liken the "tree" of a HTML document to a family tree, in which each node/person has a parent. And some nodes also have children elements, which are often referred to as nested elements.
In the example snippet below, you can think of <html> as being the root of the tree. The <head> and <body> are its children elements, and they each have a child element of their own, <title> and <h1>, respectively:
<html lang="en">
<head>
<title>Hello</title>
</head>
<body>
<h1>Some words</h1>
</body>
</html>
And that's pretty much all we need to know about HTML. Yes, there are many, many more varieties of tags and attributes. But we know enough to kind of understand the core concept of HTML: it's a particular format of text used to describe the structure of a webpage. Everything else will just be details to memorize on a need-to-remember basis.
If you want to learn a little more, here are some resources:
The Elements Panel
The Chrome DevTools Elements Panel lets us interactively explore the DOM tree of the webpage currently rendered in the browser.
On the DevTools menu bar, Elements is the first labeled item from the left. The panel contains two panes: On the left is the DOM Tree Pane. On the right is the Styles Pane, which I'll cover in the next lesson. For the current lesson on the DOM tree, you can shrink the Styles Pane by dragging the divider-line:
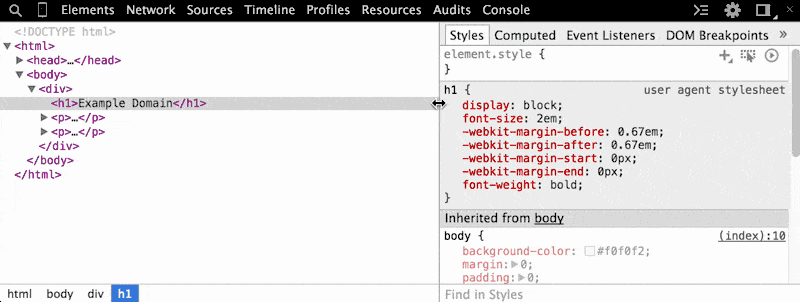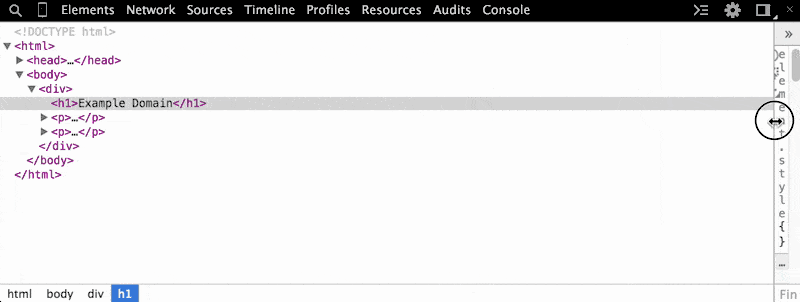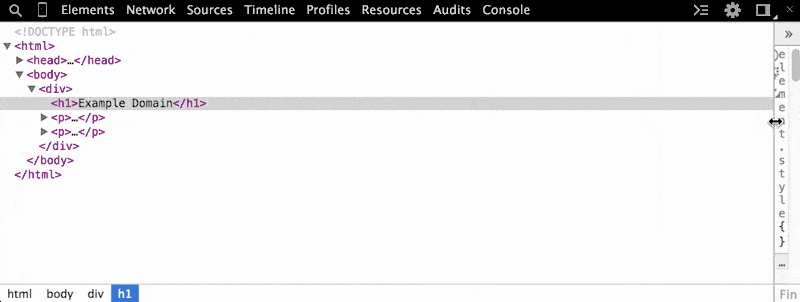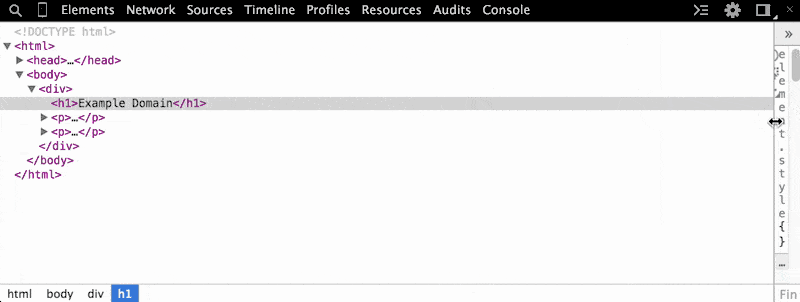
Using the "Inspect Element" pop-up menu command
Besides using the keyboard shortcut (PC: Ctrl+Shift+I / Mac: Cmd+Opt+I) to open the Dev Tools, the mouse can be used to jump right into the Elements panel:
- Right-click the element you want to inspect. This will bring up a pop-up menu.
- Select Inspect Element
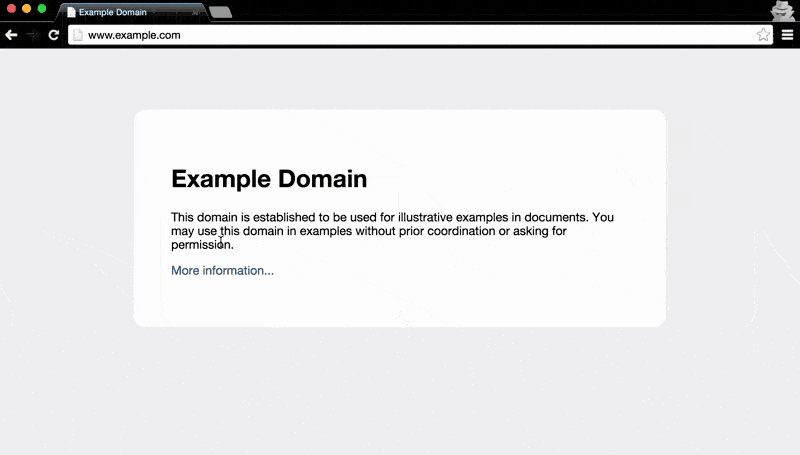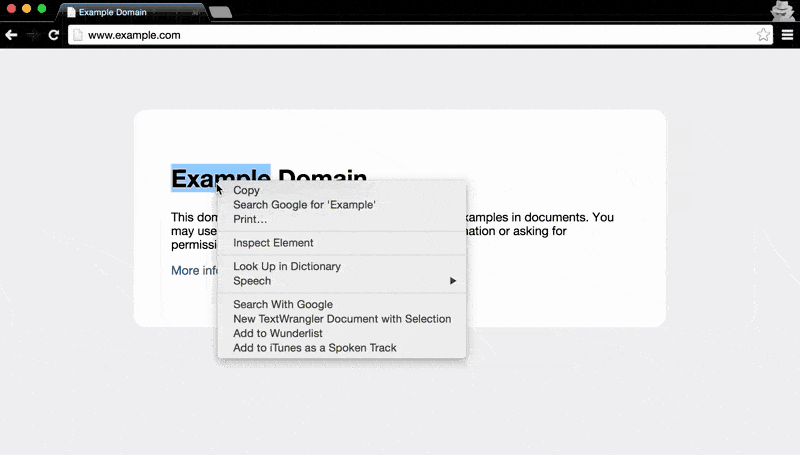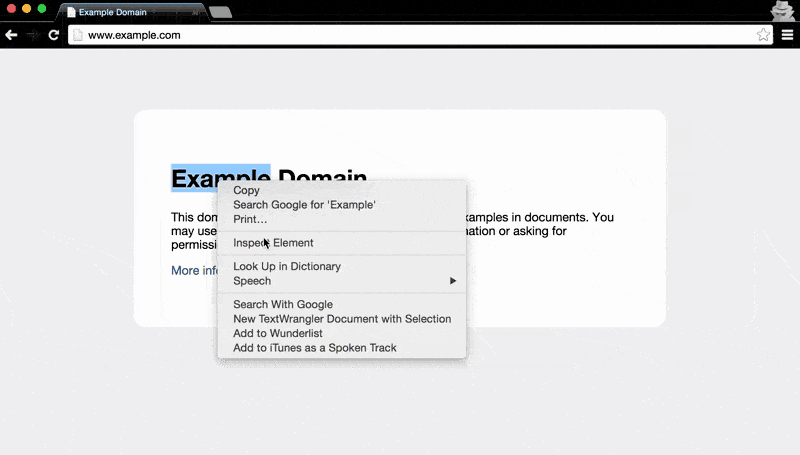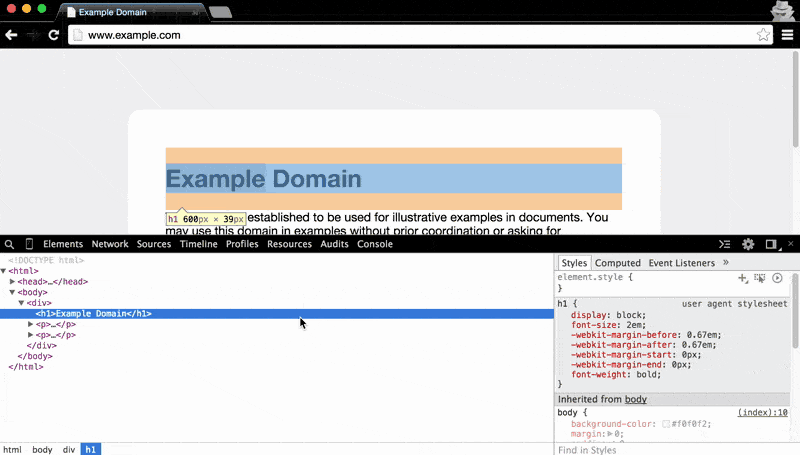
This will conveniently bring up the Elements panel and highlight the exact element we're interested in:
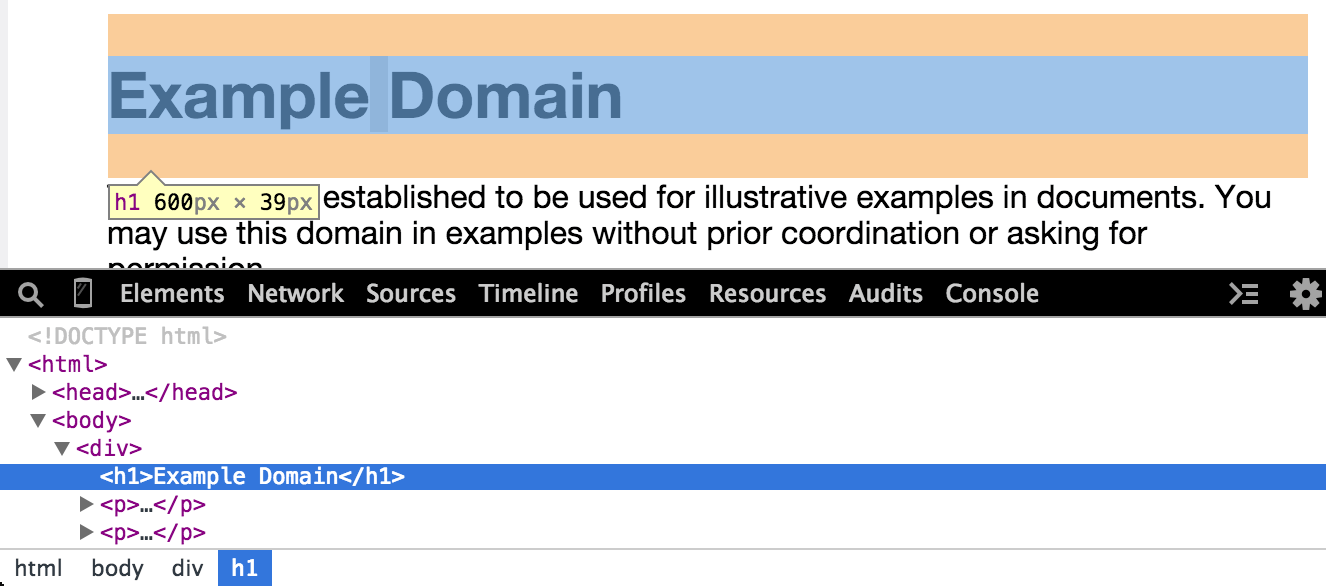
Interacting with the elements
The Elements panel makes it easy to see which bit of HTML code applies to which rendered page element. As we hover the mouse pointer over HTML code in the Elements panel, the corresponding rendered element will be highlighted. In the panel, an HTML element that contains children nodes can be expanded to show its contents by clicking the adjacent little black arrow:
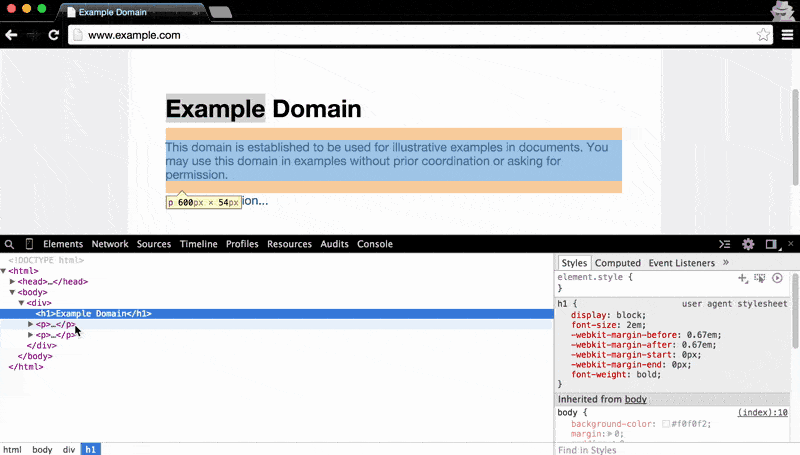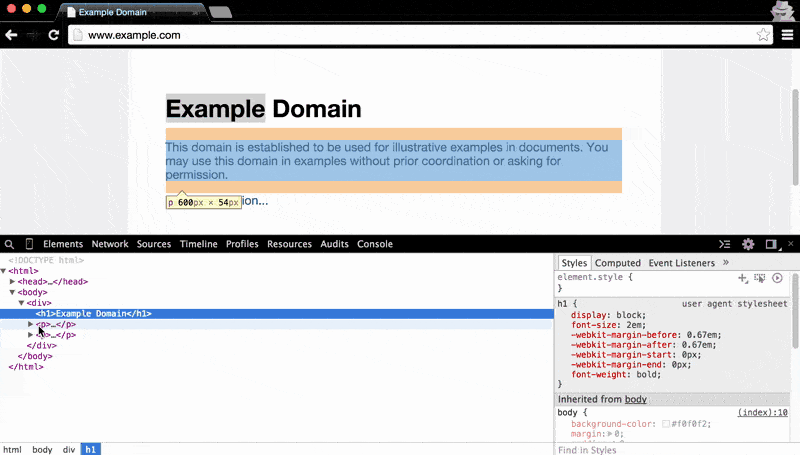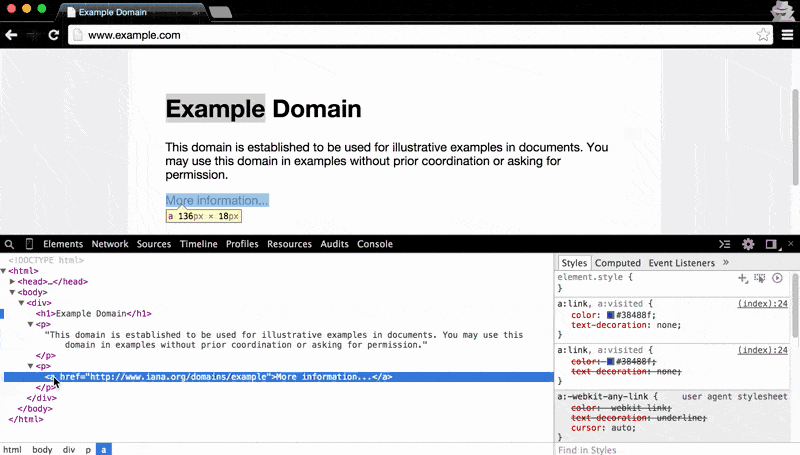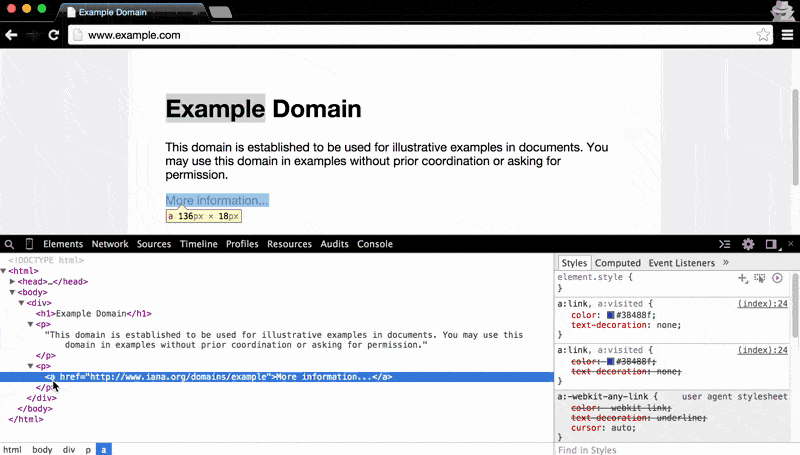
The Elements panel also makes clear the nested structure of HTML documents: hovering over the main <body> element highlights all of the visual content on the page. As you hover to each child element, from the <div> to the <h1> (i.e. the main headline, Example Domain), the visual highlight gets narrower and narrower:
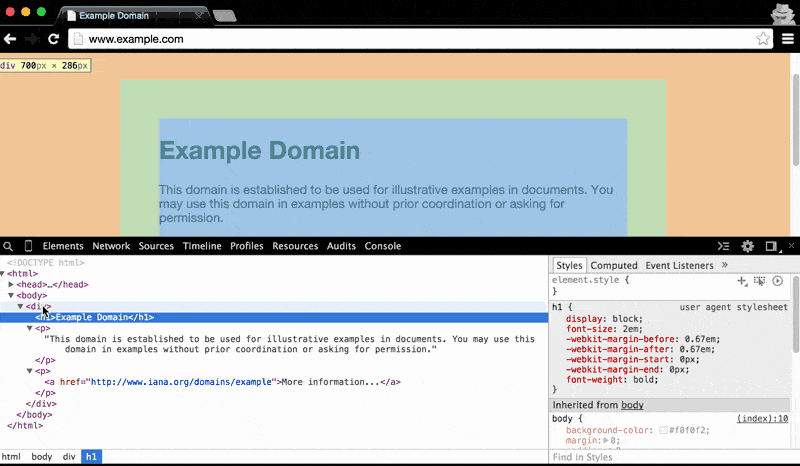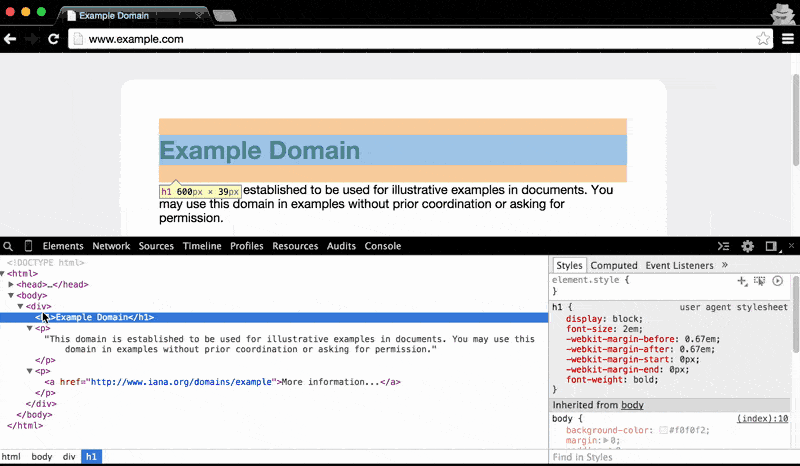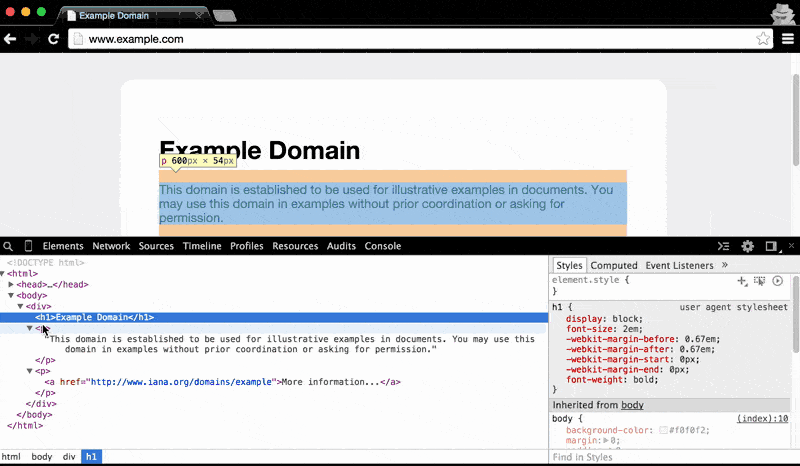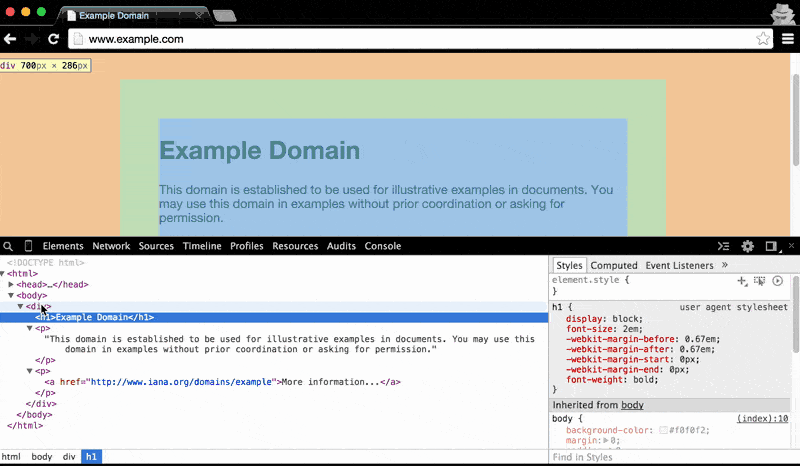
Understanding the nested structure of HTML documents will be key to effectively doing web scraping. For example, we'll often want to target elements within a given parent element, rather than all elements across the document.
The breadcrumbs bar
The webpage we've been exploring in this example is extremely simple. In practice, webpages will contain a mess of HTML code that makes it difficult to track which child elements belong to which parents.
As you hover around the elements in the DOM Tree Pane, take a look at the very bottom of the Chrome browser: there's a breadcrumbs bar that gives a one-line representation of what element we're pointing to, and all of its ancestors:
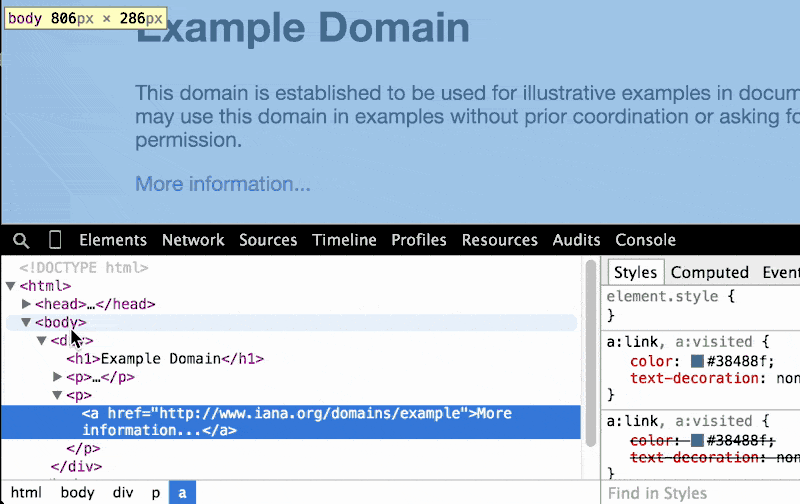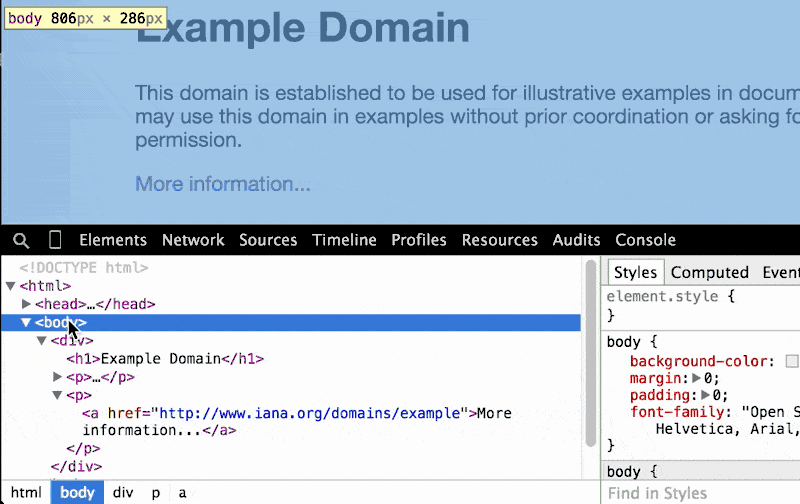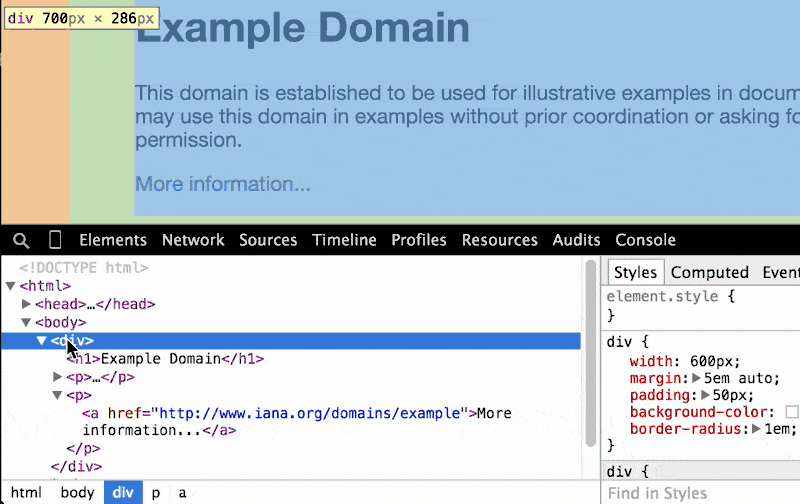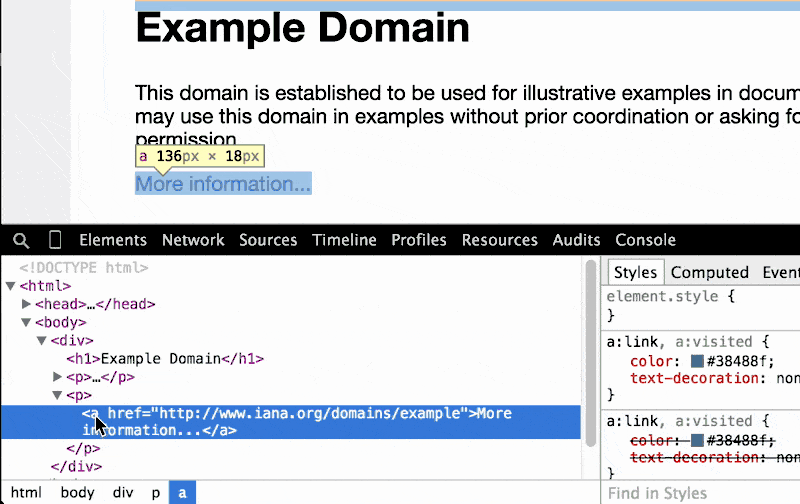
As we go deeper and deeper into the DOM tree, the breadcrumbs trail gets longer and longer:

An example web-scrape
When we write web-scraping scripts, the breadcrumbs bar makes it very easy to find a reference the exact element we want to scrape. For example, we see that the hyperlink on www.example.com/ exists at html body div p a.
To select this element in Python (using the Beautiful Soup HTML parsing library) and print the URL it points to:
import bs4
import requests
soup = bs4.Beautifrequests.get('http://www.example.com').text
print(soup.select("html body div p a")[0]['href'])
# http://www.iana.org/domains/example
What we see is not what we get
Why do we care about exploring the internals of a webpage when we have a sophisticated web browser to render the page in a friendly, usable interface? Because not every detail about a page is revealed in that interface (that's why it's actually usable). And sometimes we don't care about what the page looks like; we want the data and other files that that page refers to.
Exploring the Elements panel is an essential step in both understanding how the Web works and, more directly, accessing data without letting an interface get in our way.