A continuation of USAJobs Midterm Part 1; refer to it for the background information about the USAJobs.gov API.
This assignment continues the practice of working with JSON, lists, and dictionaries, but emphasizes a few more fundamental concepts, including:
- Reference
- Directions
- Exercises
- 2-1. * Download the job data for every country and save as JSON
- 2-2. Download the job data for every U.S. state and save as JSON
- 2-3. * Sum and print the job listings for foreign countries and for U.S. states
- 2-4. Print the U.S. job states with fewer than 100 listings
- 2-5. Print the foreign countries with more than 10 listings
- 2-6. Print the job counts for the top 10 non-US countries, and sum all others
- 2-7. * Create a Google Bar Chart and HTML table of the states
- 2-8. Print out a world Google Map with the non-US countries and a table
- 2-9. * Get first 250 jobs in California, count full time jobs
- 2-10. Get first 250 jobs in California, count jobs by Department
- 2-11. * Find the 5 highest paying jobs in California among full-time jobs
- 2-12. Find the California job with the widest range in min and max salary
- 2-13. * Find all California jobs that have been recently posted
- 2-14. Find all California jobs that pay $90K+ and have fewer than 5 days before they expire
- 2-15. Produce an interactive Google Geochart showing jobs per California city
- All Solutions
Reference
- Software Carpentry: Creating Functions in Python (swcarpentry.github.io)
- Software Carpentry: Repeating Actions with Loops
- Software Carpentry: Making Choices with Conditionals
- Think Python: Functions (greenteapress.com)
- Think Python: Conditional execution (greenteapress.com)
- Think Python: Lists
- Think Python: Dictionaries
- A short Python cheatsheet
- A long Python cheatsheet
Directions
The exercises with asterisks already have the solution. A problem with a solution usually contains hints for subsequent problems, or sometimes for the problem directly preceding it.
All the problems come with expected results, but your results may be slightly different, because the job listings change on an hourly/daily basis.
For the problems that are already done, you must still turn them in. The expectation is that you at least type them out, line by line, into iPython so each step and its effect are made clear to you.
Deliverables
Due date: Monday, May 11
Create a folder in your compjour-hw repo named: usajobs-midterm-2.
For each exercise, create a separate file, e.g.
|-- compjour-hw/
|-- usajobs-midterm-2/
|-- 2-1.py
|-- 2-2.py
(etc)
|-- 2-15.py
Some exercises may require you to produce a file. For example, exercise 2-7 requires that you create a webpage. Store that webpage in the same directory as the script files, e.g.
|-- compjour-hw/
|-- usajobs-midterm-2/
|-- 2-7.py
|-- 2-7.html
(etc)
Exercises
2-1. * Download the job data for every country and save as JSON
Using the list of country codes found here:
http://stash.compjour.org/data/usajobs/CountryCode.json
Query the USAJobs API for each country, then make a list of lists that looks like:
[
['Aruba', 0],
['Antigua and Barbuda', 0],
['Afghanistan', 12],
# ... etc
['Zimbabwe', 1],
]
Finally, save this list as JSON-formatted data, to the path:
data-hold/intl-jobcount.json
Takeaway
This (and Exercise 2) involve using one data source (a list of countries) and looping through it to gather data from another source (the USAJobs API, using the Country parameter). A relatively simple if-statement is required to filter out countries that are not the U.S.
After the loop finishes, the result should be a list that contains one entry for every country; and each entry is itself a list, containing the country name and its jobs count. Using the json library and its dumps() method, the list is serialized and saved as a textfile, data-hold/domestic-jobcount.json. Subsequent exercises can then load this datafile without having to redo the (very long) data fetching process.
So this exercise is mostly to make the next few exercises more convenient. However, make sure you understand how significant it is that a data structure from this exercise – i.e. the list – can be saved as text, and re-loaded (using json.loads()), effectively allowing multiple programs to "talk" to each other with data. Doing this process well is the foundation of most real-world data projects.
Solution
import json
import os
import requests
BASE_USAJOBS_URL = "https://data.usajobs.gov/api/jobs"
CODES_URL = "http://stash.compjour.org/data/usajobs/CountryCode.json"
cdata = requests.get(CODES_URL).json()
mylist = []
for d in cdata['CountryCodes']:
# getting non-US countries only
if d['Code'] != 'US' and d['Value'] != 'Undefined':
cname = d['Value']
print("Getting:", cname)
# we set NumberOfJobs to 1 because we don't need job listings, just
# the TotalJobs
atts = {'Country': cname, 'NumberOfJobs': 1}
resp = requests.get(BASE_USAJOBS_URL, params = atts)
data = resp.json()
# the 'TotalJobs' value is always a string, we want it as an
# int
jobcount = int(data['TotalJobs'])
mylist.append([cname, jobcount])
# save the file on to your hard drive
os.makedirs("data-hold", exist_ok = True)
f = open("data-hold/intl-jobcount.json", 'w')
f.write(json.dumps(mylist, indent = 2))
f.close()
2-2. Download the job data for every U.S. state and save as JSON
Similar to Exercise #1, except use:
http://stash.compjour.org/data/usajobs/us-statecodes.json
The list-of-lists will look something like:
[
['Alaska', 231],
['California', 750],
['Iowa', 421]
]
And save the file to:
data-hold/domestic-jobcount.json
Takeaway
Pretty much the same process as Exercise 1, except you don't need an if-statement, as the us-statecodes.json file contains only the state names you need, i.e. no filtering is required.
2-3. * Sum and print the job listings for foreign countries and for U.S. states
Note: Exercises 1 and 2 must have completed successfully before you can do this exercise.
Loop through data-hold/domestic-jobcount.json and data-hold/intl-jobcount.json, and for each collection, tally the sum of the job counts, and then print a line for each sum, i.e.
There are YY international jobs.
There are XX domestic jobs.
Takeaway
A simple summation exercise. In the given solution, I provide two ways to think about it. The first is simply to think about it as a loop: what more is there to calculating a sum than going through a list and adding up the numbers?
The second example uses Python's built-in sum() function, which, when given a sequence of numbers (e.g. a list), will return their sum. In this scenario, we don't have a list of numbers, but a list-of-lists, so I use a list comprehension, which is a " concise way to create lists":
xlist = [['apples', 10], ['oranges', 20]]
ylist = [z[1] in for z in xlist]
If you find that hard to comprehend, feel free to go with the more verbose, but perfectly fine, standard for-loop:
xlist = [['apples', 10], ['oranges', 20]]
ylist = []
for z in xlist:
ylist.append(z[1])
Result
There are 735 international jobs.
There are 12902 domestic jobs.
Solution
import json
with open("data-hold/domestic-jobcount.json") as f:
domestic_data = json.loads(f.read())
with open("data-hold/intl-jobcount.json") as f:
intl_data = json.loads(f.read())
# using standard for loop
dcount = 0
for d in intl_data:
dcount += d[1]
print("There are %s international jobs." % dcount)
# using list comprehension and sum
icount = sum([d[1] for d in domestic_data])
# note, you don't need to use a list comprehension...
# this would work too:
# icount = sum(d[1] for d in intl_data)
# ...but rather than learn about iterators right now, easier
# ...to just be consistent with list comprehensions
print("There are %s domestic jobs." % icount)
2-4. Print the U.S. job states with fewer than 100 listings
Note: Exercise 2 must have completed successfully – i.e. data-hold/domestic-jobcount.json exists – before you can do this exercise.
Open data-hold/domestic-jobcount.json (use the setup code from Exercise 2-3) and, for the states that have fewer than 100 job listings, print a comma-separated list of the state's name and job listings count. This list should be sorted by alphabetical order of state names.
Takeaway
Another loop across a list.. This exercise gets you used to doing things in steps:
- Sorting the list
- Filtering the list
Hints
Step 1 is the most difficult to do without an understanding of Python syntax and convention, i.e. you can't easily start from knowing what a for-loop is and end up with a sorted sequence.
The built-in sorted() function will take in one sequence and return a sorted copy:
listx = [3,2,4]
listy = sorted(listx)
# [2, 3, 4]
However, in this problem, we don't have a simple list of numbers. We have a list-of-lists:
domestic_list = [['Iowa', 20], ['Alabama', 45]]
However, calling sorted() on the list will actually just work, because given no further guidance, sorted() will compare the first element of each member (and again, each member of the list-to-be-sorted is a list). And since we want an alphabetically-sorted list of elements, and the first member of each list is the name of the country, we should be good to go!
Step 2, i.e. filtering the list, is pretty straightforward: use a if-statement to select and print only the states that meet the given condition (fewer than 100 job listings).
The simplest way to think of the process is to create a sorted copy of the states list in Step 1, and then iterate across that sorted copy with the for-loop and if-statement. A similar loop-and-filter process was done in Exercise 2-1.
Result
Connecticut,78
Delaware,52
Iowa,96
Maine,52
New Hampshire,66
Rhode Island,41
Vermont,31
2-5. Print the foreign countries with more than 10 listings
Open data-hold/intl-jobcount.json and, for the countries that have more than 10 job listings, print a comma-separated list of the country's name and job listings count.
Takeaway
Same principle and process as Exercise 2-4. Except the sorting process is more complicated because instead of sorting by name of country – i.e. the first element of each list – we want to sort by the second element of each list:
[['Afghanistan',12], ['Germany', 99]]
Hints
The sorted() method takes a keyword argument named key, in which you can specify the name of a function. This function should, given any member of the list-to-be-sorted, return the value that will be used to figure out where that list member should be in the sort order.
For example, let's pretend we wanted to sort by length of country name. I might define a function like so:
def myfoo(thing):
name = thing[0]
return len(name)
### usage:
# myfoo(['Germany', 99])
### returns:
# 7
To use this in sorted():
mysortedlist = sorted(mycountrieslist, key = myfoo)
So for this exercise, you have to define myfoo (or whatever you want to call it) to extract the jobs count value, i.e. the second element of a list like '['Germany', 99] – it will be even simpler than the example myfoo above.
Hint: sorted() also takes in an argument named reverse, which you can set to True if you want to get things in reverse order. Not necessary for this exercise, but more direct given that the answer requires a list of countries in descending order of total job count.
Another hint: In the previous JSON homework assignments, the solutions contain the use of itemgetter, which is a convenience method that accomplishes the same thing as the "define a custom function" solution above.
Recommended reading:
- sorting - how does operator.itemgetter and sort() work in Python? - Stack Overflow (stackoverflow.com)
- HowTo/Sorting - Python Wiki (wiki.python.org)
Result
Germany,99
Japan,57
Italy,47
South Korea,47
United Kingdom,29
Turkey,16
Bahrain,15
Portugal,14
Belgium,13
China,13
Spain,13
Afghanistan,12
2-6. Print the job counts for the top 10 non-US countries, and sum all others
Similar to Exercise 2-5, read data-hold/intl-jobcount.json and print out the top 10 countries in descending order of number of job listings as a comma-separated list. Then, include an 11th line as Other, with its total being the sum of all the jobs from the non top-10 countries.
Takeaway
You should be able to use most of the code from Exercise 2-5. However, instead of filtering the sorted list using an if-statement, you simply take the first 10 elements and print them as before. Then you take the remaining elements and sum them up into an Other category. This technique of "throwing-all-the-non-major-stuff-into-a-bucket" is extremely common and handy in data visualization, as you typically don't want to represent every possible category in a dataset (think about how useless a pie chart is with 50 slices).
Result
Germany,99
Japan,57
Italy,47
South Korea,47
United Kingdom,29
Turkey,16
Bahrain,15
Portugal,14
Belgium,13
China,13
Others,385
2-7. * Create a Google Bar Chart and HTML table of the states
Using data-hold/domestic-jobcount.json, print a webpage containing:
- A Google interactive bar chart showing the job totals for only the top 10 states with the most jobs.
- An HTML table listing the states and their job totals in descending numerical order of the job count.
Use the template HTML found here:
http://2015.compjour.org/files/code/answers/usajobs-midterm-2/sample-barchart-2.html
Results
http://2015.compjour.org/files/code/answers/usajobs-midterm-2/2-7.html
Solution
import json
from operator import itemgetter
## assumes you've made a copy of this file
# http://stash.compjour.org/files/code/answers/usajobs-midterm/sample-barchart-2.html
# and stashed it at a relative path:
# sample-barchart-2.html
with open("sample-barchart-2.html") as f:
htmlstr = f.read()
with open("data-hold/domestic-jobcount.json") as f:
data = json.loads(f.read())
sorteddata = sorted(data, key = itemgetter(1), reverse = True)
# Just charting the top 10 states
chartdata = [['State', 'Jobs']]
chartdata.extend(sorteddata[0:10])
# include all the states
tablerows = []
for d in sorteddata:
tablerows.append("<tr><td>%s</td><td>%s</td></tr>" % (d[0], d[1]))
tablerows = "\n".join(tablerows)
#
with open("2-7.html", "w") as f:
htmlstr = htmlstr.replace('#CHART_DATA#', str(chartdata))
htmlstr = htmlstr.replace('#TABLE_ROWS#', tablerows)
f.write(htmlstr)
2-8. Print out a world Google Map with the non-US countries and a table
Similar to Exercise 2-7, except use data-hold/intl-jobcount.json and instead of printing a bar chart, use a Interactive Google Geochart to produce a map of only the foreign countries that have at least 1 job.
Use this Geochart template and replace the placeholder-text as necessary:
http://2015.compjour.org/files/code/answers/usajobs-midterm-2/sample-geochart-2.html
Results
http://2015.compjour.org/files/code/answers/usajobs-midterm-2/2-8.html
Solution
2-9. * Get first 250 jobs in California, count full time jobs
Query the USAJobs API to get 250 job listings. From those job listings, count the number of jobs that are considered full-time jobs.
At the end of the script, print() the resulting dictionary.
Takeaway
This is one small example of what "dirty data" looks like. It'd be nice if the 'WorkSchedule' attribute contained a list of predictable values, i.e. "Full-time" for jobs that are full-time…but a quick examination of all the job entries shows that apparently, the USAJobs system lets people type in arbitrary text:
# assuming that `data` is a response from USAJobs.gov
jobterms = set()
for job in data['JobData']:
jobterms.add(job['WorkSchedule'])
print(jobterms)
The result looks like:
{'This is a full-time position.', 'Part Time 50 hours', 'Permanent', 'Full Time', 'Part Time', 'Full-time', 'Part Time .5 hours', 'Intermittent', 'Part Time 48 hours', 'Multiple Schedules', 'Full-Time', 'Shift Work', 'Part Time 16 hours', 'Part Time 5 hours', 'Part-Time', 'Term', 'Work Schedule is Full Time.'}
So the trick to this problem is coming up with some kind of conditional that will get all the variations of work schedules that are used for full-time work, e.g. "Full Time", "Full-Time", 'This is a full-time position.'
Results
{'Other': 43, 'Full-time': 207}
Solution
import requests
BASE_USAJOBS_URL = "https://data.usajobs.gov/api/jobs"
resp = requests.get(BASE_USAJOBS_URL, params = {"CountrySubdivision": 'California', 'NumberOfJobs': 250})
data = resp.json()
mydict = {'Full-time': 0, 'Other': 0}
for job in data['JobData']:
if 'full' in job['WorkSchedule'].lower():
mydict['Full-time'] += 1
else:
mydict['Other'] += 1
print(mydict)
2-10. Get first 250 jobs in California, count jobs by Department
Same query of the USAJobs API as in Exercise 2-9, but create a Dictionary in which the keys are the organization name, e.g. "Department of Veterans Affairs" and "Department Of Homeland Security".
At the end of the script, print() the resulting dictionary.
Takeaway
This is similar to Exercise 2-9, except that you don't have to use a conditional to filter by terms; you just need to create a dictionary that contains a key for each possible organization name, with the value being equal to how many times a job showed up under that organization name.
If you want, you can try to figure out the Counter class, though it's not necessary.
Results
{'Other Agencies and Independent Organizations': 13, 'Department of the Air Force': 13, 'Department Of Transportation': 4, 'General Services Administration': 2, 'Department Of Justice': 3, 'Department Of Health And Human Services': 5, 'Department Of Homeland Security': 14, 'National Aeronautics and Space Administration': 3, 'Department of the Army': 24, 'Department of Defense': 7, 'Department Of Energy': 1, 'Department of the Navy': 46, 'Department Of Labor': 3, 'Department Of Veterans Affairs': 78, 'Department Of The Interior': 16, 'Department Of Agriculture': 18}
2-11. * Find the 5 highest paying jobs in California among full-time jobs
Using a static JSON file that contains a snapshot of all of the California jobs, sort the list by the maximum possible salary amount and print the 5 highest-paying jobs as a comma-separated list of: the job title, the minimum salary, the maximum salary.
About the static JSON file
Sometime ago, I ran a script to download all of the job listings for California and then combined the results into one large page, which you can download here:
http://stash.compjour.org/data/usajobs/california-all.json
It's a pretty big file, so in the posted solution, I've included some code that downloads and saves the file to disk, and on subsequent runs, uses that same file so you don't have to keep repeating the download.
As it is a compilation of several USAJobs data pages, I've saved it in my own JSON format. Don't expect TotalJobs or JobData to be the attributes, for instance. And to remind me of when I actually downloaded the file, I've included a date_collected attribute, which will be useful for Exercises 2-13 and 2-14.
Takeaway
We haven't yet written a script to paginate through all the results of the USAJobs API for a given state/country. So this will do for now for the remaining exercises in this assignment.
Results
Staff Physician (Neurosurgeon),98967,375000
Physician (Thoracic Surgeon - Scientist),98967,375000
Physician (General Surgery),99957,355000
Anesthesiologist (Chief, Pain Management),200000,340000
Physician (Anesthesiologist),99957,325000
Solution
import json
import requests
import os
## for subsequent exercises
## copy this data-loading snippet
CA_FILE = 'data-hold/california.json'
if not os.path.exists(CA_FILE):
print("Can't find", CA_FILE, "so fetching remote copy...")
resp = requests.get("http://stash.compjour.org/data/usajobs/california-all.json")
f = open(CA_FILE, 'w')
f.write(resp.text)
f.close()
rawdata = open(CA_FILE).read()
jobs = json.loads(rawdata)['jobs']
## end data-loading code
# val is a string that looks like "$45,000"
# the return value is a Float: 45000.00
def cleanmoney(val):
x = val.replace('$', '').replace(',', '')
return float(x)
# job is Dictionary object; perform the cleanmoney() function on the
# 'SalaryMax' value and return it
def cleansalarymax(job):
return cleanmoney(job['SalaryMax'])
# sort the jobs list based on the result of cleansalarymax
sortedjobs = sorted(jobs, key = cleansalarymax, reverse = True)
for job in sortedjobs[0:5]:
print('%s,%d,%d' % (job['JobTitle'], cleanmoney(job['SalaryMin']), cleanmoney(job['SalaryMax'])))
2-12. Find the California job with the widest range in min and max salary
Using the data dump of all California jobs, filter for jobs that have a max salary under $100,000. From this list, find the job with the biggest difference between minimum and maximum salary.
Print the result as a single line of comma-separated values: job title, minimum salary, maximum salary. (there is only one answer)
Results
CFPB Pathways Recent Graduate (Public Notice Flyer),29735,93380
2-13. * Find all California jobs that have been recently posted
Using the data dump of all California jobs, calculate the number of days since each job posting has been on the list (i.e. its StartDate) relative to the time it was collected, i.e. how many days the job has been on the list since the data file was collected.
Sort the job listings by the number of days they've been on the list, then filter it to show just jobs that have been on the list 2 days or fewer.
Then print the listings as comma-separated values: job title, days since the job was first posted, and the URL to apply for the job
The data dump contains an attribute named date_collected for you to use.
Takeaway
This is a short tour through the hell that can come from turning seemingly simple datetime strings, e.g. "January 15, 2014" and 2012-01-01 05:20:30, into datetime objects.
Why would you want to turn "January 15, 2014" into a "datetime" object? Because it seems handy to be able to do something like this:
"January 20, 2015" - "11/3/2007"
# 2635 days
Of course you can't subtract one string from another. But if you convert them to a datetime object, then you have the ability to compare different dates and easily figure out the difference between two dates, i.e. how many days or hours or seconds have passed between them. When you consider all the complex things that have to be taken into account, such as how each month has a different number of days, and then leap years, calculating the chronological distance between time is something best left to the computer.
Sample usage:
from datetime import datetime
d1 = '11/3/2007'
d2 = 'January 20, 2015'
date1 = datetime.strptime(d1, '%m/%d/%Y')
date2 = datetime.strptime(d2, '%B %d, %Y')
timediff = date2 - date1
timediff.days
# 2635
timediff.total_seconds()
# 227664000.0.0
What is that business with datetime.strptime() and '%m/%d/%Y'? As you should've guessed by now, there's no way that the Python interpreter is smart enough to figure out whether "11/3/2007" means "November 3, 2007", as per the American convention; or "March 11, 2007", as per most of the rest of the world's convention. So we pass a specially formatted string, e.g. '%m/%d/%Y', into strptime() to tell it exactly what each number stands for.
In other words, time-format strings represent one more thing about programming you have to memorize. Luckily, the conventions (e.g. %Y for a 4-digit-year) are mostly shared between all the modern languages.
More reading:
- strftime() and strptime() Behavior
- python - Calculating Time Difference - Stack Overflow (stackoverflow.com)
Results
Note: Only the first 10 results are shown below; there are 39 results total (you may get a few more because of differences in timezone calculation. Some things have a -1 day value…I filtered those out…for no reason at all…you can leave them in or include a condition to just show listings with 0 days or less)
Procurement Technician,0,https://www.usajobs.gov/GetJob/ViewDetails/401978100?PostingChannelID=RESTAPI
Legal Administrative Specialist (Litigation Support),0,https://www.usajobs.gov/GetJob/ViewDetails/401913100?PostingChannelID=RESTAPI
Restorative Care Coordinator,0,https://www.usajobs.gov/GetJob/ViewDetails/401975100?PostingChannelID=RESTAPI
Legal Assistant (OA),0,https://www.usajobs.gov/GetJob/ViewDetails/401959500?PostingChannelID=RESTAPI
Biological Science Technician,0,https://www.usajobs.gov/GetJob/ViewDetails/398381400?PostingChannelID=RESTAPI
Professional Engineers,0,https://www.usajobs.gov/GetJob/ViewDetails/401557200?PostingChannelID=RESTAPI
PHYSICIAN (FAMILY PRACTICE),0,https://www.usajobs.gov/GetJob/ViewDetails/401943100?PostingChannelID=RESTAPI
Environmental Engineer, GS-0819-13,0,https://www.usajobs.gov/GetJob/ViewDetails/401930100?PostingChannelID=RESTAPI
Recreation Aid (Outdoor Recreation) NF-0189-01,0,https://www.usajobs.gov/GetJob/ViewDetails/402032500?PostingChannelID=RESTAPI
Realty Specialist,0,https://www.usajobs.gov/GetJob/ViewDetails/401972000?PostingChannelID=RESTAPI
Solution
import json
import requests
import os
from datetime import datetime
CA_FILE = 'data-hold/california.json'
if not os.path.exists(CA_FILE):
print("Can't find", CA_FILE, "so fetching remote copy")
resp = requests.get("http://stash.compjour.org/data/usajobs/california-all.json")
f = open(CA_FILE, 'w')
f.write(resp.text)
f.close()
rawdata = open(CA_FILE).read()
jdata = json.loads(rawdata)
jobs = jdata['jobs']
collection_date = datetime.strptime(jdata['date_collected'], '%Y-%m-%dT%H:%M:%S')
## end job-loading code
def daysonlist(job):
postdate = datetime.strptime(job['StartDate'], '%m/%d/%Y')
return (collection_date - postdate ).days
for job in sorted(jobs, key = daysonlist):
days = daysonlist(job)
if days <= 2:
print('%s,%s,%s' % (job['JobTitle'], days, job['ApplyOnlineURL']))
2-14. Find all California jobs that pay $90K+ and have fewer than 5 days before they expire
Similar to Exercise 2-13. Again, use the date_collected attribute found in the data dump. You'll also want to re-use the string-cleaning function (for converting "$44,000" to 44000) from Exercise 2-11.
Print the listings as comma-separated values: job title, days left on the list, and the URL to apply for the job
Results
Only the first 10 out of 24 (you may get a few more because of differences in timezone calculation. Some results may have a -1 day value…I filtered those out…for no reason at all…you can leave them in or include a condition to just show listings with 0 days or less) results are posted here:
Clinical Pharmacist (Oncologist),0,https://www.usajobs.gov/GetJob/ViewDetails/401242000?PostingChannelID=RESTAPI
RNP-Registered Nurse Practitioner (Home Based Primary Care),0,https://www.usajobs.gov/GetJob/ViewDetails/400951900?PostingChannelID=RESTAPI
RNP-Registered Nurse Practitioner (Home Based Primary Care),0,https://www.usajobs.gov/GetJob/ViewDetails/400952000?PostingChannelID=RESTAPI
Clinical Pharmacist (PACT Pain ),1,https://www.usajobs.gov/GetJob/ViewDetails/400783200?PostingChannelID=RESTAPI
Clinical Pharmacist (PACT Pain ),1,https://www.usajobs.gov/GetJob/ViewDetails/401246000?PostingChannelID=RESTAPI
Physician (Associate Chief of Staff for Research),2,https://www.usajobs.gov/GetJob/ViewDetails/392131900?PostingChannelID=RESTAPI
Physician (Occupational Medicine),2,https://www.usajobs.gov/GetJob/ViewDetails/396122300?PostingChannelID=RESTAPI
INTERDISCIPLINARY (SCIENTIST/ENGINEER),2,https://www.usajobs.gov/GetJob/ViewDetails/401080800?PostingChannelID=RESTAPI
Interdisciplinary Engineer,2,https://www.usajobs.gov/GetJob/ViewDetails/401176400?PostingChannelID=RESTAPI
Physician (Obstetrics/Gynecology),2,https://www.usajobs.gov/GetJob/ViewDetails/395916500?PostingChannelID=RESTAPI
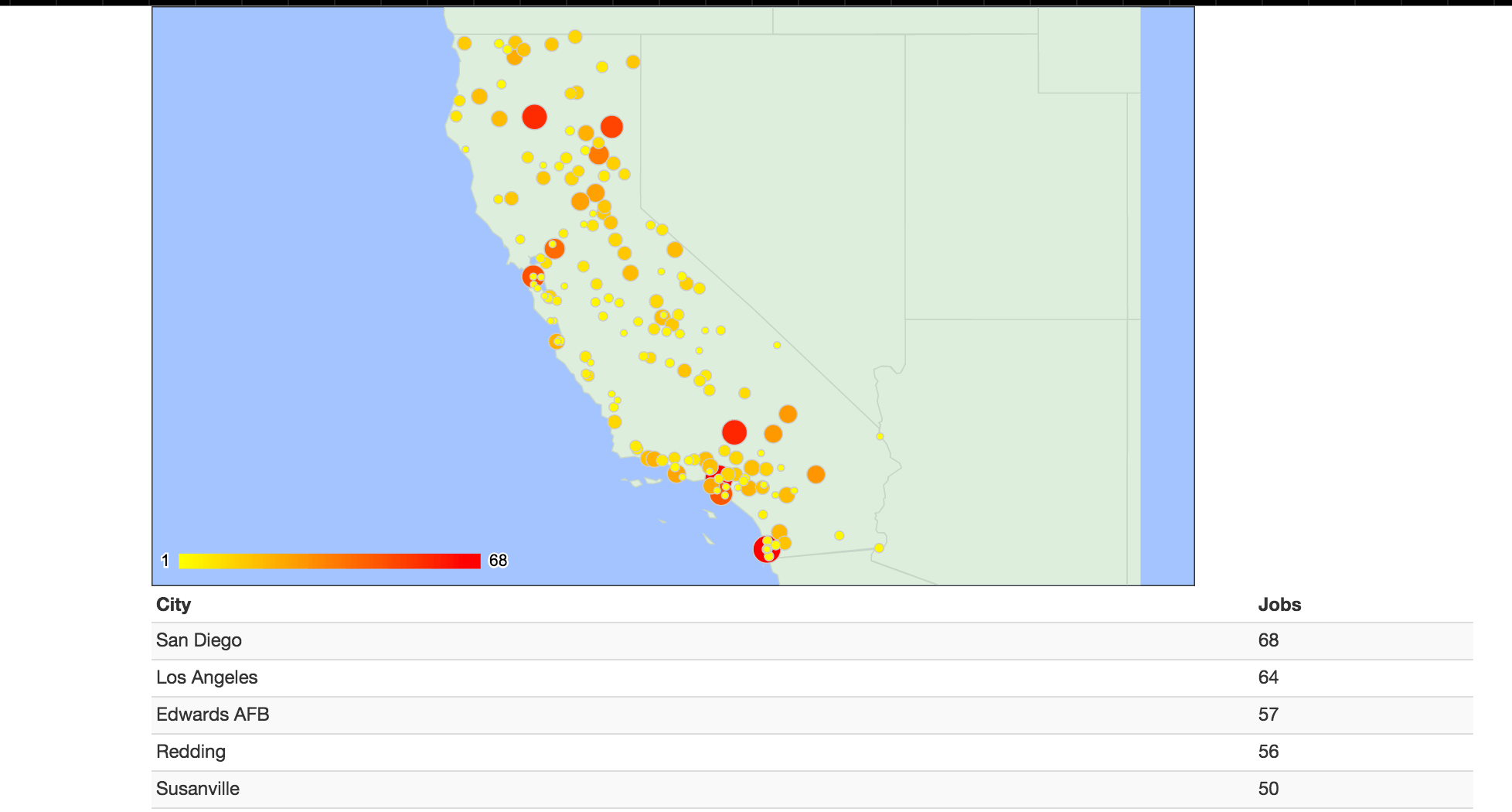
2-15. Produce an interactive Google Geochart showing jobs per California city
Create a interactive Google Geochart with markers indicating how many jobs there are per California city.
Each job listing has a Locations attribute containing a string that looks like this:
'Los Angeles, California;San Francisco, California;Chicago, Illinois;New City, New York;San Antonio, Texas'
Some jobs have more than one city attributed to them, and some have non-California cities.
Pretend the jobs listing consisted of just two jobs, and that they had Locations values that looked like this:
'Los Angeles, California;San Francisco, California;Chicago, Illinois'
'San Francisco, California;Albany, New York'
You need to produce a list that looks like:
[
['Los Angeles', 1]
['San Francisco', 2]
]
Which you then feed into the HTML for a Interactive Google Geochart, as in previous exercises (here's a live working example).
Use this HTML template for the map:
http://2015.compjour.org/files/code/answers/usajobs-midterm-2/sample-geochart-cities.html
Hints
I recommend defining a function named get_ca_cities() that operates like so:
# `job` is one of the job listings in the job_data dump
print(job['Locations'])
# Print result is a string:
# 'Los Angeles, California;Denver, Colorado;District of Columbia, District of Columbia;Atlanta, Georgia;Dallas, Texas;Seattle, Washington'
xlist = get_ca_cities(job)
print(xlist)
# ['Los Angeles']
type(xlist)
# list
Given a Dictionary object, get_ca_cities should read its "Locations" value, and parsing it into a list that contains only the first name of California cities. If the "Locations" value doesn't contain any reference to "California", then return an empty list.
Counting up the cities
Once you get_ca_cities() function works, and you run it for every job listing, you'll end up with a list of list of strings, e.g.
[
['Los Angeles'],
['Los Angeles', 'San Francisco'],
['Palo Alto'],
]
Counting them up can be done in a similar fashion as done in Exercise 2-10.
The Marker Geocharts
I've already written up a sample template for you to use, but if you're curious, take a look at the documentation for the Marker Geocharts. Notice in the given example that the region of IT (Italy) is given, and in the data list, only the names of the cities are used, e.g. "Rome", "Florence".
Results
http://2015.compjour.org/files/code/answers/usajobs-midterm-2/2-14.html
All Solutions
2-1.
import json
import os
import requests
BASE_USAJOBS_URL = "https://data.usajobs.gov/api/jobs"
CODES_URL = "http://stash.compjour.org/data/usajobs/CountryCode.json"
cdata = requests.get(CODES_URL).json()
mylist = []
for d in cdata['CountryCodes']:
# getting non-US countries only
if d['Code'] != 'US' and d['Value'] != 'Undefined':
cname = d['Value']
print("Getting:", cname)
# we set NumberOfJobs to 1 because we don't need job listings, just
# the TotalJobs
atts = {'Country': cname, 'NumberOfJobs': 1}
resp = requests.get(BASE_USAJOBS_URL, params = atts)
data = resp.json()
# the 'TotalJobs' value is always a string, we want it as an
# int
jobcount = int(data['TotalJobs'])
mylist.append([cname, jobcount])
# save the file on to your hard drive
os.makedirs("data-hold", exist_ok = True)
f = open("data-hold/intl-jobcount.json", 'w')
f.write(json.dumps(mylist, indent = 2))
f.close()
2-2.
import json
import os
import requests
BASE_USAJOBS_URL = "https://data.usajobs.gov/api/jobs"
STATECODES_URL = "http://stash.compjour.org/data/usajobs/us-statecodes.json"
names = requests.get(STATECODES_URL).json()
mylist = []
for name in names.keys():
print("Getting:", name)
resp = requests.get(BASE_USAJOBS_URL, params = {'CountrySubdivision': name, 'NumberOfJobs': 1})
jobcount = int(resp.json()['TotalJobs'])
mylist.append([name, jobcount])
os.makedirs("data-hold", exist_ok = True)
f = open("data-hold/domestic-jobcount.json", 'w')
f.write(json.dumps(mylist, indent = 2))
f.close()
2-3.
import json
with open("data-hold/domestic-jobcount.json") as f:
domestic_data = json.loads(f.read())
with open("data-hold/intl-jobcount.json") as f:
intl_data = json.loads(f.read())
# using standard for loop
dcount = 0
for d in intl_data:
dcount += d[1]
print("There are %s international jobs." % dcount)
# using list comprehension and sum
icount = sum([d[1] for d in domestic_data])
# note, you don't need to use a list comprehension...
# this would work too:
# icount = sum(d[1] for d in intl_data)
# ...but rather than learn about iterators right now, easier
# ...to just be consistent with list comprehensions
print("There are %s domestic jobs." % icount)
2-4.
import json
with open("data-hold/domestic-jobcount.json") as f:
domestic_list = json.loads(f.read())
for v in sorted(domestic_list):
if v[1] < 100:
print("%s,%s" % (v[0], v[1]))
2-5.
import json
with open("data-hold/intl-jobcount.json") as f:
intl_list = json.loads(f.read())
def myfoo(x):
return x[1]
for d in sorted(intl_list, key = myfoo, reverse = True):
if d[1] > 10:
print("%s,%s" % (d[0], d[1]))
2-6.
import json
from operator import itemgetter
with open("data-hold/intl-jobcount.json") as f:
data = json.loads(f.read())
sorted_data = sorted(data, key = itemgetter(1), reverse = True)
for d in sorted_data[0:10]:
print("%s,%s" % (d[0], d[1]))
others = sum([d[1] for d in sorted_data[10:-1]])
print("Others,%s" % others)
2-7.
import json
from operator import itemgetter
## assumes you've made a copy of this file
# http://stash.compjour.org/files/code/answers/usajobs-midterm/sample-barchart-2.html
# and stashed it at a relative path:
# sample-barchart-2.html
with open("sample-barchart-2.html") as f:
htmlstr = f.read()
with open("data-hold/domestic-jobcount.json") as f:
data = json.loads(f.read())
sorteddata = sorted(data, key = itemgetter(1), reverse = True)
# Just charting the top 10 states
chartdata = [['State', 'Jobs']]
chartdata.extend(sorteddata[0:10])
# include all the states
tablerows = []
for d in sorteddata:
tablerows.append("<tr><td>%s</td><td>%s</td></tr>" % (d[0], d[1]))
tablerows = "\n".join(tablerows)
#
with open("2-7.html", "w") as f:
htmlstr = htmlstr.replace('#CHART_DATA#', str(chartdata))
htmlstr = htmlstr.replace('#TABLE_ROWS#', tablerows)
f.write(htmlstr)
2-8.
import json
from operator import itemgetter
with open("sample-geochart-2.html") as f:
htmlstr = f.read()
with open("data-hold/intl-jobcount.json") as f:
data = json.loads(f.read())
sorteddata = sorted(data, key = itemgetter(0))
# Just charting countries with at least 10 jobs
chartdata = [['Country', 'Jobs']]
for d in sorteddata:
if d[1] >= 10:
chartdata.append([d[0], d[1]])
# include all the countries in the table
tablerows = []
for d in sorteddata:
tablerows.append("<tr><td>%s</td><td>%s</td></tr>" % (d[0], d[1]))
tablerows = "\n".join(tablerows)
#
with open("2-8.html", "w") as f:
htmlstr = htmlstr.replace('#CHART_DATA#', str(chartdata))
htmlstr = htmlstr.replace('#TABLE_ROWS#', tablerows)
f.write(htmlstr)
2-9.
import requests
BASE_USAJOBS_URL = "https://data.usajobs.gov/api/jobs"
resp = requests.get(BASE_USAJOBS_URL, params = {"CountrySubdivision": 'California', 'NumberOfJobs': 250})
data = resp.json()
mydict = {'Full-time': 0, 'Other': 0}
for job in data['JobData']:
if 'full' in job['WorkSchedule'].lower():
mydict['Full-time'] += 1
else:
mydict['Other'] += 1
print(mydict)
2-10.
import requests
BASE_USAJOBS_URL = "https://data.usajobs.gov/api/jobs"
resp = requests.get(BASE_USAJOBS_URL, params = {"CountrySubdivision": 'California', 'NumberOfJobs': 250})
data = resp.json()
my_dict = {}
for job in data['JobData']:
orgname = job['OrganizationName']
if my_dict.get(orgname):
my_dict[orgname] += 1
else:
my_dict[orgname] = 1
print(mydict)
2-11.
import json
import requests
import os
## for subsequent exercises
## copy this data-loading snippet
CA_FILE = 'data-hold/california.json'
if not os.path.exists(CA_FILE):
print("Can't find", CA_FILE, "so fetching remote copy...")
resp = requests.get("http://stash.compjour.org/data/usajobs/california-all.json")
f = open(CA_FILE, 'w')
f.write(resp.text)
f.close()
rawdata = open(CA_FILE).read()
jobs = json.loads(rawdata)['jobs']
## end data-loading code
# val is a string that looks like "$45,000"
# the return value is a Float: 45000.00
def cleanmoney(val):
x = val.replace('$', '').replace(',', '')
return float(x)
# job is Dictionary object; perform the cleanmoney() function on the
# 'SalaryMax' value and return it
def cleansalarymax(job):
return cleanmoney(job['SalaryMax'])
# sort the jobs list based on the result of cleansalarymax
sortedjobs = sorted(jobs, key = cleansalarymax, reverse = True)
for job in sortedjobs[0:5]:
print('%s,%d,%d' % (job['JobTitle'], cleanmoney(job['SalaryMin']), cleanmoney(job['SalaryMax'])))
2-12.
import json
import requests
import os
CA_FILE = 'data-hold/california.json'
if not os.path.exists(CA_FILE):
print("Can't find", CA_FILE, "so fetching remote copy")
resp = requests.get("http://stash.compjour.org/data/usajobs/california-all.json")
f = open(CA_FILE, 'w')
f.write(resp.text)
f.close()
rawdata = open(CA_FILE).read()
jobs = json.loads(rawdata)['jobs']
## end job-loading code
def cleanmoney(val):
x = val.replace('$', '').replace(',', '')
return float(x)
def cleansalaryspread(job):
return cleanmoney(job['SalaryMax']) - cleanmoney(job['SalaryMin'])
smalljobs = [job for job in jobs if cleanmoney(job['SalaryMax']) < 100000]
job = max(smalljobs, key = cleansalaryspread)
print('%s,%d,%d' % (job['JobTitle'], cleanmoney(job['SalaryMin']), cleanmoney(job['SalaryMax'])))
2-13.
import json
import requests
import os
from datetime import datetime
CA_FILE = 'data-hold/california.json'
if not os.path.exists(CA_FILE):
print("Can't find", CA_FILE, "so fetching remote copy")
resp = requests.get("http://stash.compjour.org/data/usajobs/california-all.json")
f = open(CA_FILE, 'w')
f.write(resp.text)
f.close()
rawdata = open(CA_FILE).read()
jdata = json.loads(rawdata)
jobs = jdata['jobs']
collection_date = datetime.strptime(jdata['date_collected'], '%Y-%m-%dT%H:%M:%S')
## end job-loading code
def daysonlist(job):
postdate = datetime.strptime(job['StartDate'], '%m/%d/%Y')
return (collection_date - postdate ).days
for job in sorted(jobs, key = daysonlist):
days = daysonlist(job)
if days <= 2:
print('%s,%s,%s' % (job['JobTitle'], days, job['ApplyOnlineURL']))
2-14.
import json
import requests
import os
from collections import Counter
from operator import itemgetter
CA_FILE = 'data-hold/california.json'
if not os.path.exists(CA_FILE):
print("Can't find", CA_FILE, "so fetching remote copy")
resp = requests.get("http://stash.compjour.org/data/usajobs/california-all.json")
f = open(CA_FILE, 'w')
f.write(resp.text)
f.close()
rawdata = open(CA_FILE).read()
jdata = json.loads(rawdata)
jobs = jdata['jobs']
def get_ca_cities(job):
cities = [c for c in job['Locations'].split(';') if 'California' in c]
return [c.split(',')[0] for c in cities]
cityjobs = []
for job in jobs:
cityjobs.extend(get_ca_cities(job))
citylist = list(Counter(cityjobs).items())
# convert those tuples into lists
citylist = [list(t) for t in citylist]
# and then sort it by jobcount
chartdata = [['City', 'Jobs']]
chartdata.extend( citylist )
#####
# now create tablerows
sortedlist = sorted(citylist, key = itemgetter(1), reverse = True)
tablerows = []
for d in sortedlist:
tablerows.append("<tr><td>%s</td><td>%s</td></tr>" % (d[0], d[1]))
tablerows = "\n".join(tablerows)
outs = open("2-14.html", "w")
## assumes you've made a copy of this file
# http://stash.compjour.org/files/code/answers/usajobs-midterm/sample-geochart-cities.html
# and stashed it at a relative path:
# sample-geochart-cities.html
with open("sample-geochart-cities.html") as f:
htmlstr = f.read()
htmlstr = htmlstr.replace('#CHART_DATA#', str(chartdata))
htmlstr = htmlstr.replace('#TABLE_ROWS#', tablerows)
outs.write(htmlstr)
outs.close()